【论文笔记】One2Any: One-Reference 6D Pose Estimation for Any Object
One2Any: One-Reference 6D Pose Estimation for Any Object
| 方法 | 类型 | 训练输入 | 推理输入 | 输出 | pipeline |
|---|---|---|---|---|---|
| One2Any | 任意级 | RGBDs | RGBDs | 相对\(\mathbf{R}, \mathbf{t}\) |
- 2025.05.19:One2Any估计两张RGBD间的相对位姿,从NOCS中获得启发,One2Any直接从Ref中得到规范空间,使用Umeyama算法,将后续的Query与这个规范空间对齐,得到相对位姿。
Abstract
1. Introduction
2. Related Works
3. Method
3.1. Overview
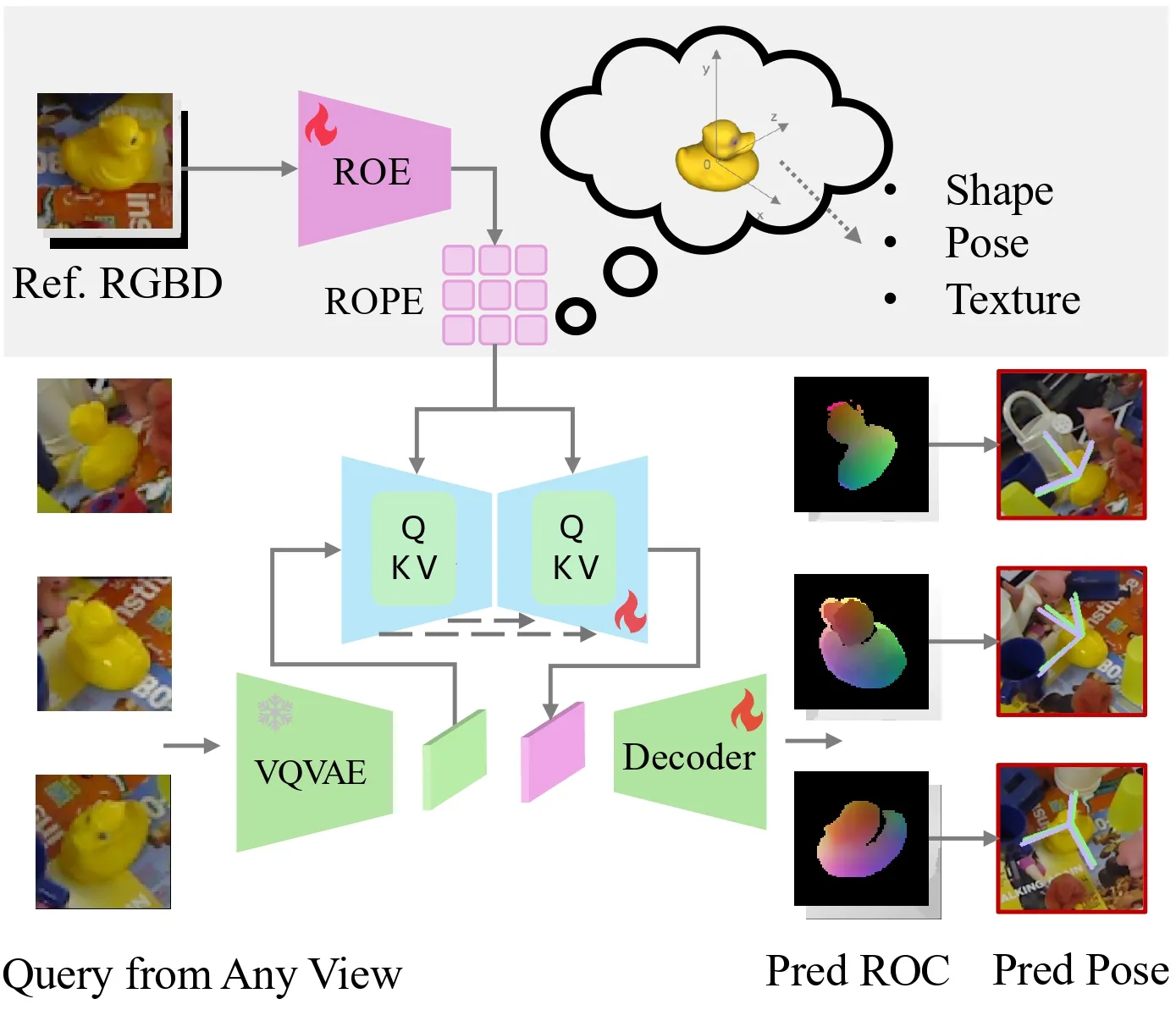
![Figure 2. Network architecture. The network takes a reference RGB-D image as input and learns a Reference Object Pose Embedding (ROPE) through a Reference Object Encoder (ROE). This embedding is subsequently integrated with the query feature map, which is extracted using a pre-trained VQVAE model [48] with the query RGB image as input. We use the U-Net architecture for effective integrate the ROPE with the query feature with cross-attentions layers. The decoder is trained to predict the ROC map. The final pose estimation is computed using the Umeyama algorithm [53].](https://img.032802.xyz/paper-reading/2025/one2any-one-reference-6d-pose-estimation-for-any-object_2025_Liu/architecture.webp)
我们将问题表述为:给定单张参考RGBD图像和查询RGBD图像的相对物体位姿估计,且不依赖CAD模型或多视角图像。 给定一幅参考RGBD图像,其RGB图像为\(A_I \in \mathbb{R}^{W \times H \times 3}\),深度图像为\(A_D \in \mathbb{R}^{W \times H}\),目标物体掩码为\(A_M \in \{0, 1\}^{W \times H}\),我们的目标是预测查询图像输入\(Q_I \in \mathbb{R}^{W \times H \times 3}\)、\(Q_D \in \mathbb{R}^{W \times H}\)、\(Q_M \in \{0, 1\}^{W \times H}\)中目标物体相对于参考视角中目标物体的位姿\([\mathbf{R} | \mathbf{t}]\)。我们的核心思想是学习一个具有参数\(\theta_A\)的参考物体编码器(ROE)\(f_A\),将参考输入\(A = [A_I, A_D, A_M]\)嵌入到参考物体位姿嵌入(ROPE)中。通过在大型数据集上训练\(f_A\),嵌入向量\(\mathbf{e}_A\)为物体位姿解码(OPD)模块提供条件,以生成查询图像的参考物体坐标(ROC)图。我们在图2中展示了网络架构。OPD模块包含用于提取查询图像特征并预测ROC图的编码器-解码器架构,这通过使用U-Net架构与ROPE集成得到进一步增强。在此,我们将具有参数\(\theta_Q\)的\(g_{\theta_Q}\)记为OPD模块,其将查询图像\(Q\)作为输入以预测输出ROC:\(Y_Q \in \mathbb{R}^{W \times H \times 3}\)。于是,我们可以将整体问题表述为:
\[ \begin{equation}\label{eq1} Y_Q = g(Q, f_A(A; \theta_A); \theta_Q) \end{equation} \]
3.2. Reference Object Coordinate (ROC)
![Figure 3. ROC representations given a reference RGB-D image and a query RGB-D image. The ROC space is initially defined by the reference frame, using the camera intrinsics \mathbf{K} and the scaling matrix \mathbf{S} to a normalized space. The query image is subsequently aligned to this space using the relative pose [\mathbf{R} | \mathbf{t}] and the scale matrix \mathbf{S}. The ROC map is generated by mapping points in the ROC space to their corresponding 2D pixel locations and encoding the point positions as RGB values.](https://img.032802.xyz/paper-reading/2025/one2any-one-reference-6d-pose-estimation-for-any-object_2025_Liu/ROC_representation.webp)
如3.1节所述,我们的目标是估计单张参考图像\(A\)与单张查询图像\(Q\)之间的相对位姿\([\mathbf{R} | \mathbf{t}]\)。为此,我们受NOCS启发,提出使用一种称为参考物体坐标(ROC)的2D-3D映射。与NOCS不同的是,我们的方法无需规范坐标系,而是直接在参考相机坐标系中表示物体坐标。因此,ROC仅由参考坐标系定义,查询图像中的物体需变换至与参考坐标系对齐,并归一化到ROC空间中。
尽管这一改动看似简单,但对训练和推理均有重要影响。根据定义,NOCS要求将同一类别的所有物体对齐到单一规范空间,而ROC图的生成要容易得多,仅需一对参考图像和查询图像,即可直接为相对位姿估计提供合适的表示。
为了从参考视图构建ROC,我们首先通过深度值反投影像素坐标来获取参考物体的部分点云\(P_A\):
\[ \begin{equation}\label{eq2} P_A = \mathbf{K}^{-1}A_D[A_M = 1] \end{equation} \]
然后,我们通过对\(P_A\)的齐次坐标应用变换\(\mathbf{S} \in \mathbb{R}^{4 \times 4}\)来获得ROC。
\[ \begin{equation}\label{eq3} Y_A = \mathbf{S}P_A \end{equation} \]
在此对符号稍作扩展,我们将映射\(A_I \to Y_A\)的ROC记为\(Y_A\)。类似地,为了获取查询图像的ROC真实值,我们首先使用真实相对位姿\([\mathbf{R} | \mathbf{t}]\)变换将查询点云转换到参考视图下,然后应用相同的缩放和平移变换\(\mathbf{S}\)。
\[ \begin{equation}\label{eq4} Y_Q = \mathbf{S}([\mathbf{R} | \mathbf{t}]P_Q) \end{equation} \]
图3展示了构建ROC图的过程。图的上半部分显示了从参考RGBD图像生成ROC图\(Y_A\)的过程,下半部分则展示了真实查询ROC图\(Y_Q\)的生成过程。该方法基于参考坐标系建立了一个物体空间,该空间会随着参考物体及其位姿的变化而动态调整。
3.3. Reference Object Pose Embedding
在仅给定单张RGBD参考图像的情况下,对查询RGBD图像进行位姿预测面临着独特的挑战。以往的方法通常依赖关键点特征匹配,如“High-resolution open-vocabulary object 6D pose estimation”、“POPE: 6-DoF Promptable Pose Estimation of Any Object, in Any Scene, with One Reference”和“NOPE: Novel Object Pose Estimation from a Single Image”,但当图像中的可见区域重叠度较低或被严重遮挡时,这些方法就会失效。我们提出了一种替代方法,将参考图像编码为参考物体位姿嵌入(ROPE),从而能够有效地预测物体位姿。我们的目标是训练一个参考物体编码器(ROE),使其能够从单张RGBD参考图像中在潜在空间生成全面的物体表示。然后,ROPE表示可以从同一物体的任何测试图像中有效地预测参考相机空间中的ROC图,从而实现准确的位姿估计。
ROE记为\(f(A; \theta_A)\),其设计目的是从由参考RGB图像、参考ROC图和物体掩码组成的通道级联输入\(A\)中提取潜在空间编码。如图2所示,该编码捕获了纹理和几何信息。编码器通过三个带残差连接的卷积层“Deep Residual Learning for Image Recognition”处理输入,生成特征图,并将其标记化为带位置嵌入的补丁“An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”。这种条件嵌入可有效引导ROC图的生成,即使在存在遮挡的情况下也能保持对参考数据的保真度,如4.8节所示。
3.4. Object Pose Decoding with ROPE
OPD模块\(g(Q, f ; \theta_Q)\)基于从参考图像中提取的ROPE,对查询图像中的物体位姿进行解码。在具有代表性的ROPE的强监督下,OPD模块通过生成查询图像的ROC图来预测物体的位姿。
OPD架构采用了受Stable Diffusion启发的编码器-解码器结构。为了更好地聚合ROPE表示,我们通过交叉注意力层集成来自查询图像的信息。具体来说,我们使用“High-resolution open-vocabulary object 6D pose estimation”中预训练的VQVAE模型来充分提取查询RGB图像\(Q_I\)的特征图,并进一步提升模型的泛化能力。我们随后通过交叉注意力层,对以代表性ROPE为条件的类UNet网络“High-resolution open-vocabulary object 6D pose estimation”进行微调。图2展示了详细架构。该U-Net通过交叉注意力机制整合查询特征\(\mathcal{F}^Q\)和参考嵌入\(\mathcal{F}^A\)(即ROPE)。具体而言,在每个交叉注意力层中,查询特征\(\mathcal{F}^Q\)与来自\(\mathcal{F}^A\)的键\(k \in \mathbb{R}^{m \times d_k}\)和值嵌入\(v \in \mathbb{R}^{m \times d_v}\)进行交互。
\[ \begin{equation}\label{eq5} k = \mathcal{F}^A \times W_k, \quad v = \mathcal{F}^A \times W_v, \quad \mathcal{F}^Q = \mathcal{F}^Q \times W_q \end{equation} \]
其中\(W\)表示每个向量的权重矩阵,且交叉注意力应用于查询向量\(q\)、键向量\(k\)和值向量\(v\)之间,
\[ \begin{equation}\label{eq6} \text{Attention}(q, k, v) = \text{softmax}\left(\frac{qk^T}{\sqrt{d_k}}\right)v \end{equation} \]
\(d_k\)是键向量\(k\)的维度,用于缩放操作,该操作在注意力机制中用于确保梯度稳定。最终的相对特征图\(\mathcal{F}^{Q2A}\)通过U-Net架构中的多个交叉注意力层实现。该架构使网络能够充分提取嵌入在ROPE中的位姿-形状信息。
解码器随后对\(F^{Q2A}\)进行逐步细化和上采样,将其重建为原始图像尺寸。该解码器由五个包含残差连接和双线性上采样的卷积层构成,生成ROC图\(\hat{Y}_Q\),其准确表示了查询视图在ROC空间中的坐标。
ROC map loss. 遵循NOCS的方法,我们通过使用平滑L1损失函数,来自“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”,监督ROC图预测值\(\hat{Y}_Q\)与真实ROC图\(Y_Q\)的一致性来训练网络\(\{f, g\}\),损失函数定义为:
\[ \begin{equation}\label{eq7} \begin{aligned} \mathcal{L} &= \frac{1}{N} \sum_i \sum_j Q_M(i, j)E(i, j) \\ c &= Y_Q(i, j) - \hat{Y}_Q(i, j) \\ E(i, j) &= \begin{cases} \frac{0.5(c)^2}{\beta}, & (|c| < \beta) \\ |c| - 0.5\beta, & \text{otherwise} \end{cases} \end{aligned} \end{equation} \]
\(\beta\)为平滑阈值,设置为0.1。对于物体掩码像素位置,\(Q_M(i, j)=1\),否则为0。
3.5. Pose Estimation from ROC Map
相对位姿\([\mathbf{R} | \mathbf{t}]\)通过测量预测的ROC图\(\hat{Y}_Q\)与查询视点云\(P_Q\)之间的变换来计算。注意,参考相机的位姿为\([\mathbf{I}_3 | \mathbf{0}]\)。首先,我们使用参考ROC的缩放矩阵的逆\(\mathbf{S}^{-1}\)对预测的ROC图\(\hat{Y}_Q\)进行平移和缩放,使其与参考相机坐标系对齐。由此得到的点云\(\hat{P}_Q^A\)表示参考相机坐标系下的查询物体。结合查询点云\(P_Q\),我们使用Umeyama方法来获取查询坐标系与参考坐标系之间的位姿预测\([\hat{\mathbf{R}} | \hat{\mathbf{t}}]\)。数学上,我们可以将其表示为:
\[ \begin{equation}\label{eq8} \begin{aligned} \hat{P}_Q^A &= \mathbf{S}^{-1}\hat{Y}_Q[Q_M = 1] \\ [\hat{\mathbf{R}} | \hat{\mathbf{t}}] &= \text{Umeyama}(P_Q, \hat{P}_Q^A) \end{aligned} \end{equation} \]
4. Experimental Results
![Figure 4. Qualitative results on YCB-Video [60] and LINEMOD [20] datasets. Predicted poses are displayed in green and groundtruth poses are in pink. We present FoundationPose [57] with the generated CAD models from the reference image (the top is the view close to the reference image, and the bottom is the view close to the query image), and we display Oryon [9] with the predicted correspondences. For our method, we also show the generated ROC map (bottom) compared with the GT ROC map (top).](https://img.032802.xyz/paper-reading/2025/one2any-one-reference-6d-pose-estimation-for-any-object_2025_Liu/linemod_ycbv_results.webp)